Lecture 01 Notes
Directed acyclic graphs
Statistical models process data but to provide scientific insight, we need scientific/causal models. Causes of data cannot be extracted from the data alone.
Causal inference is the prediction of intervention and imputation of missing observations.
- Causal prediction: knowing a cause means being able to predict the consequences of an intervention (“what if I do this?”).
- Causal imputation: knowing a cause means being able to construct unobserved counterfactual outcomes (“what if I had done something else?”).
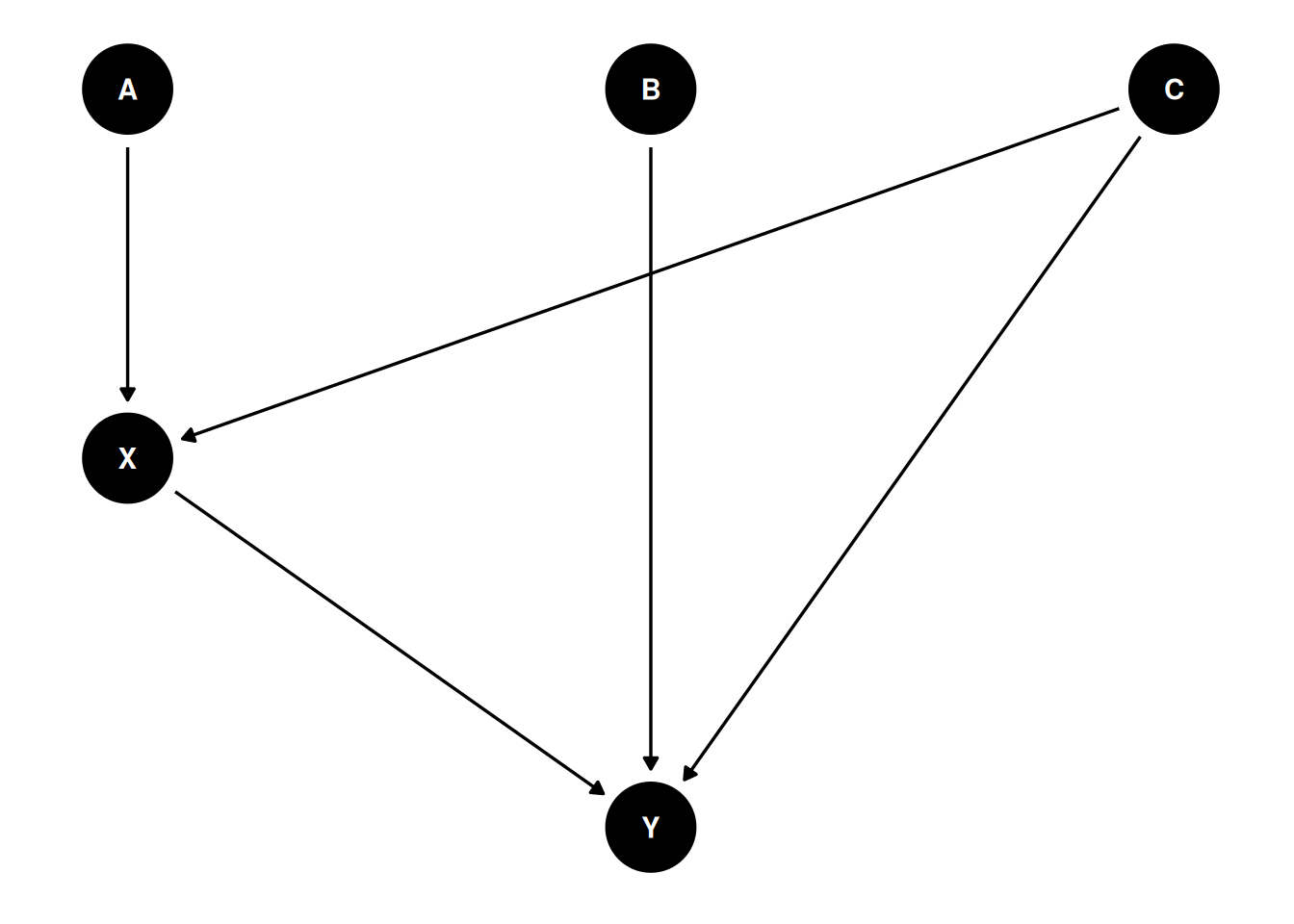
- X is a treatment
- Y is an outcome
- B is a competing cause of Y
- A is an influence of the treatment X
- C is a common cause of X and Y (a confound)
Relationships between all variables can impact outcomes.
Note
DAGs inherently represent unidirectional relationships at one moment in time with variable influencing other variables. Reciprocal relationships can be drawn in DAGs using multiple variables for different time periods eg. intelligence (youth) → educational attainment → income → intelligence (adult) (Rohrer 2018).
DAGs are not specific to one model and therefore can be used for different queries and related models. These different models should not necessarily include all variables, and DAGs help us determine appropriate controls for each question. DAGs are logically specific and can be used to test and refine the causal model.
Causes are always something to consider regardless if the application is descriptive or inferential because a sample always differs from the population, and we must think about the causes of this difference.
DAGs are transparent scientific assumptions to
- justify scientific effort
- expose scientific assumptions to useful critique
- connect theories to statistical models
Golems
Statistical models are powerful but dangerous and have no wisdom or foresight. Flowcharts of tests that are isolated for specific uses are not intuitive or appropriate for research science. Null hypothesis rejection is not appropriate, feasible or ethical in many contexts.
Reflect
What are other process models that are consistent with this same fact?
Owls
Emphasis on documenting and testing code, using a respectable workflow
- Theoretical estimand
- Scientific (causal) model
- Use the theoretical estimand and the scientific model to build a statistical model
- Simulate from the scientific model to validate that the statistical model yields the theoretical estimand
- Analyse the real data